Project Summary
What is the purpose of studying computer science? To make simple things more complicated, (but to hopefully to save some time in the long run).
I have two blogs. Both hosted on substack. One is a travel blog, that I started writing at the beginning of 2025. I started the year off backpacking and spent 6 months doing travel and writing about it. The other is a tech blog, that I just recently started (writing this in October of 2025).
I also recently started building this personal website and wanted to integrate my blogs posts into them. I wanted to do a little more than just hyperlink to Substack, so I decided to make a project out of it.
RSS stands for “Really Simple Syndication” and is a feed that publishers normally keep the content they distribute. What is generally in an RSS feed is essentially the data and metadata from posts formatted in XML. It’s very common among news websites for instance. You can see more examples here if you’re interested.
Lucky for me, Substack has public RSS feeds for their blogs. I was able to use this to parse out the important metadata from my blogs that I wanted to post on my website (title, header image, subtitle, link to substack). Using this I was able to populate my website pages with data that mirrors what substack provides, but hosted on my own infrastructure.
An alternative to using the RSS page, is that I could have just parsed the individual blog post pages, but that would be a bit of a pain going to each page and defining each of the URLs in my script. RSS scripts are purposefully made for this so why not use them.
Now, I could have just done all this manually, but where’s the fun in that?
I decided to take it a step further and update my script into a cron job to check and automatically my website when I post new blogs. I update the scripts implementation and packaged it up as a docker container and deployed it as an AWS Lambda function. Using AWS EventBridge, I added logic to trigger the lambda once a day, so when I post a new blog on substack, it’ll identify the new post, parse the needed data from the file and update my datastores, so that my website’s blog sections will reflect the new substack posts.
Since this script should run without me having to manage it, I put in thorough logging and exception handling. This way if an error occurs part of the script fails, I’ll have documentation as to where the error occurred so that I can trouble shoot and iterate.
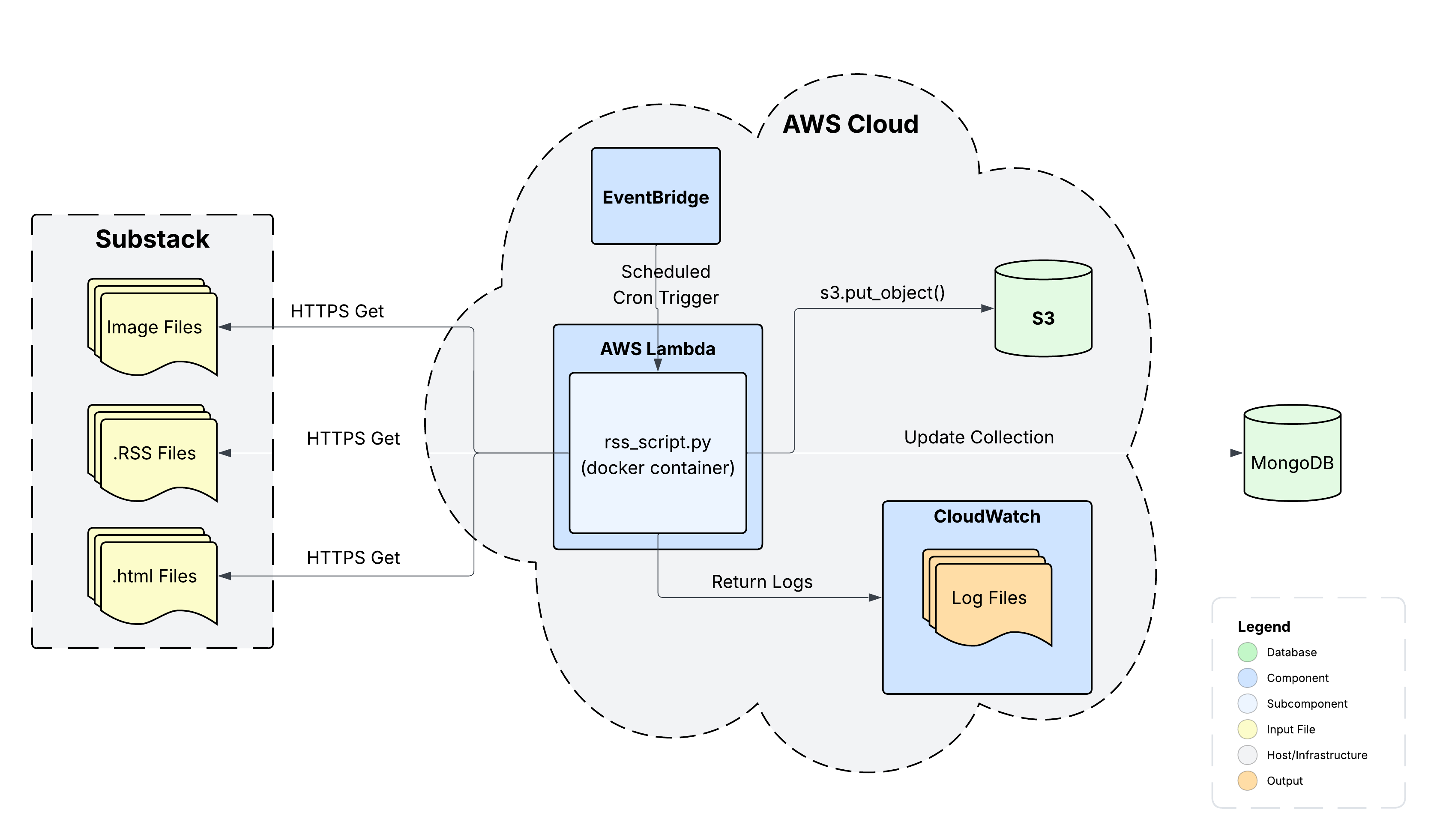
(System Diagram)
System Components
- rss_script.py: parse .rss files for posts, upload data to DBs, packaged as docker container
- Substack Servers: Serves .rss data and holds blog images
- AWS Lambda: FaaS deployment of rss_script.py
- Mongo DB: Data stores for blog post’s text metadata
- AWS S3: Data store for blog images
- AWS EventBridge: Execute cron job once a day
- AWS CloudWatch: Logging
Inputs
- Substack .rss files: Separate files for each blog
- Substack Blog Post .html files: HTML files for individual blog post
- Substack Images: Image files stored in substack CDN
Outputs
- Log Files: Documents success or failures + errors
- Images: Downloaded images from substack
- Metadata: Parsed metadata from substack
Dependencies
- xml.etree: parse xml in .rss files
- requests: handles http requests
- BeautifulSoup: Parse html
- Boto3: SDK for S3
- Pymongo: Handles MongoDB interactions
Code + High Level Program Description
Code Accessible at: https://github.com/jbelshe/rss_substack_parser
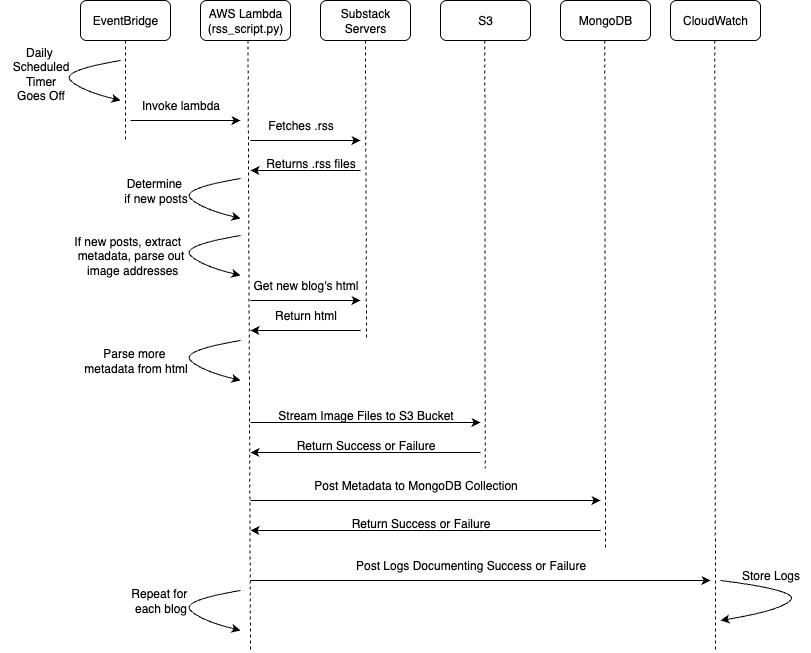
(RSS Parsing Sequence Diagram)
Alright, so the general flow for how this works, is each night at midnight pacific time, the cron job I have on AWS EventBridge gets triggered. This has a nice internal wiring from EventBridge to Lambda since their both in the AWS ecosystem.
The Lambda function is a docker container holding the python script that I have deployed with its necessary dependencies (see list above).
The first thing the script must do is determine if there are any new posts. Since it runs every night, the majority of executions will result in no actions taking place. To check if there is a new post, the script sends a request to MongoDB and gets the most recent timestamp for the requested blog.
To determine if there has been a new blog post, the script retrieves the .rss file from the Substack endpoint. It then parses the most recent blog post and compares the dates between the two posts. If the post from the substack .rss file has a fresher timestamp, then it indicates that there is one or more new blog posts. If this is not the case, there is no new data and the script can return true and shut down.
If there is a new post, this triggers the rest of the processing. The .rss data continues to be parsed one post at a time, while the post is fresher than the most recent timestamp in MongoDB. In the .rss file, the URL of the blog post is parsed and so is the URL of the post’s primary image. The .html code is retrieved from the blog post’s URL and is parsed for further metadata. This metadata along with the .rss metadata is packaged up and store in a MongoDB collection that is accessed by my personal website. The image URL is then retrieved and the image is downloaded and streamed to the S3 bucket that I use for my website images.
If all this goes smoothly, I log which new posts are created for each of my blogs (if any are) and an indication of success or failure. These logs are automatically uploaded to CloudWatch after the lambda executes.
If the whole process was a success, then the following day after posting a new blog, the post should be reflected in my blog page on my website with the content being accurately served from MongoDB and S3.